

Unlocking Precision: Abstractive Summarization and the Power of Retrieval-Augmented Generation (RAG)


In the realm of natural language processing (NLP), summarizing text effectively is a key challenge. Two primary techniques are used: extractive summarization and abstractive summarization. While extractive summarization pulls direct sentences from the original text, abstractive summarization goes a step further, generating entirely new sentences that encapsulate the main ideas of the source material. Unlike extractive summarization, which selects and combines sentences directly from the original text, abstractive summarization generates new sentences that capture the essence of the original document[1,2].
- Condensation of Information: It aims to reduce the length of the original text while retaining the key points and essential information.
- Generation of New Text: Instead of directly copying sentences from the source, it creates new sentences that convey the same meaning.
- Paraphrasing: It often involves rephrasing the original content to make the summary more readable and succinct.
- Synthesis: It integrates and combines information from different parts of the text to provide a coherent and unified summary.
Traditional methods in abstractive summarization, such as word frequency and discourse semantics, are based on relatively simple algorithms. Word frequency methods determine the importance of words or phrases by counting their occurrences in the text[3]. This approach assumes that words appearing more frequently are more important to the overall meaning of the text. Discourse semantics[4], on the other hand, focuses on the structure and meaning of the text at a higher level, aiming to produce summaries that reflect the underlying discourse.Recent advances in abstractive summarization have been driven by the development of sophisticated models and techniques. Pre-trained encoders, such as BERT (Bidirectional Encoder Representations from Transformers), have significantly improved the quality of summaries by leveraging large amounts of pre-trained data to better understand and represent the input text.
These models can capture complex relationships between words and phrases, leading to more coherent and contextually accurate summaries.Sequence-to-sequence models[6,7,8], like BART (Bidirectional and Auto-Regressive Transformers) and Pegasus, have also revolutionized abstractive summarization. These models use transformer architectures to generate summaries, allowing them to consider the entire input text and produce more coherent and contextually relevant summaries.
By learning to generate text one token at a time, these models can produce summaries that are more fluent and natural-sounding.Furthermore, the advent of Large Language Models (LLMs) such as GPT-3 (Generative Pre-trained Transformer 3) has further advanced the field of abstractive summarization[9,10,11].
LLMs are trained on massive amounts of text data and are capable of understanding and generating human-like text. This makes them particularly well-suited for summarization tasks, as they can generate summaries that are not only accurate but also stylistically similar to human-written summaries.The field of abstractive summarization has seen significant advancements in recent years, driven by the development of pre-trained encoders, sequence-to-sequence models, and Large Language Models. These advancements have led to substantial improvements in the quality and effectiveness of abstractive summarization systems, showcasing the rapid progress in the field of natural language processing.
Why Do We Need RAG with language models?
Even though LLMs are trained on a vast amount of data, they sometimes fall short due to:
- Outdated Data: The information they are trained on can become outdated.
- Costly Retraining: Updating the model with new data requires expensive and time-consuming retraining.
- Limited Context: LLMs may lack in-depth industry- or organization-specific context.
- Inaccuracies: LLMs may generate responses that are incorrect, some as grave as hallucinations.
- Lack of Explainability: LLMs can’t verify, trace, or cite sources.
Introducing Retrieval-Augmented Generation (RAG)
RAG is a technique to ground your LLMs to generate responses to your queries based on a custom knowledge-base that you provide. RAG enhances LLMs by allowing them to access up-to-date information from specific sources or an organization’s own knowledge base. This keeps the model's responses accurate and relevant without needing to retrain the whole model.RAG can greatly benefit abstractive summarization with LLMs. The main benefits from RAG can be broadly classified into two categories - factual accuracy and personalization.
Factual accuracy
Retrieval-Augmented Generation (RAG) can boost the factual accuracy of large language models (LLMs) by integrating external, up-to-date information into their outputs. This process ensures that responses are derived from the most current and reliable data, enhancing their trustworthiness and precision.Sometimes, summarizing documents requires additional knowledge that isn't present in the original source document or query. Rather than depending solely on the LLM to utilize the extensive data it was trained on to infer this extra information, we can employ Retrieval-Augmented Generation (RAG) to supply the necessary context. By retrieving relevant information from external databases, RAG greatly diminishes the occurrence of hallucinations[12] or factually incorrect generations, thus enhancing the reliability of the content [13]. This combination of retrieval and generation capabilities allows for responses that are both contextually appropriate and informed by the latest and most accurate information. Consequently, RAG represents a significant advancement in the development of more intelligent and versatile language models. [13,14].
Personalization
Personalizing a Large Language Model (LLM) involves adapting its behavior to better suit the preferences and needs of individual users[15]. As Large Language Models (LLMs) have become more prevalent, there is a growing interest in how to utilize these models to improve personalization. In the context of summarization, tailoring a summary to user preferences is highly desired. One common approach is to incorporate all of historical user data into the model's input. However, this can lead to lengthy inputs that exceed system limits, resulting in delays and increased costs [16]. A no-brainer option is finetuning on user data but this usually ends up being time consuming and, usually causes over-specialization to the fine-tuning tasks, and harm the model’s pre-existing generalization ability on unseen tasks via in-context learning[32]. As a middle ground, current techniques focus on selectively retrieving relevant user data to generate prompts for specific tasks[17]. Recent work has shown promise in combining retrieval approaches with LLMs to improve personalized performance in recommender systems [18, 19, 20], as well as general NLP tasks [21, 22, 23].
RAG Framework
The Retrieval-Augmented Generation (RAG) framework encompasses several essential steps. Initially, text inputs, such as documents or queries, undergo an embedding phase where they are converted into numerical representations called embeddings. These embeddings capture the semantic meaning of the text and facilitate efficient storage and retrieval. Subsequently, the embeddings are stored in a database, serving as the foundation for the RAG system's knowledge base. During the indexing phase, the embeddings are organized to enable rapid retrieval, creating an index that maps embeddings to their respective documents or passages. When a user query is presented, the RAG system searches the index to locate the most relevant embeddings. The system then retrieves the corresponding documents or passages from the database, which serve as context for generating a response. In some instances, the retrieved documents may be ranked based on their relevance to the query. Finally, using the retrieved documents and the input query, the RAG system generates a response, often employing pre-trained language models to produce text that aligns with the query's intent. Through these steps, the RAG framework enhances the accuracy and relevance of responses in natural language processing tasks. Let’s go through the three most researched areas here : Embedding creation, retrieval methods and generation.

Embedding Creation
Embeddings are numerical representations of objects or concepts. In NLP, embeddings are often used to represent words or phrases. These embeddings are generated by algorithms that analyze the context in which words appear in a large corpus of text. The goal is to capture semantic relationships between words, such that similar words have similar embeddings. This allows algorithms to understand the meaning of words based on their context and enables tasks like sentiment analysis, machine translation, and text summarization. For clarity, see the image below for a simple depiction of a high-dimensional vector space:
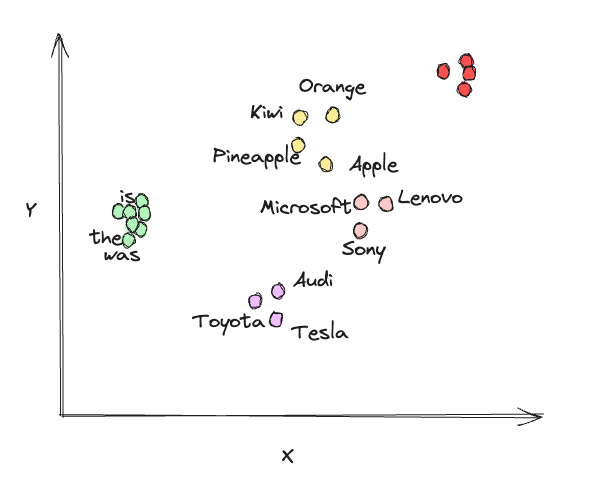
Embedding models are algorithms specifically created to learn and produce embeddings for a given piece of information. There are different ways of creating embeddings. Sparse methods, like BM25 and TF-IDF, count how many times each word appears in a piece of text to create these representations. However, these representations are very sparse, meaning they are mostly zeros and can be as long as the number of unique words in a language. Sparse methods are easy to understand and use, but they might not be great at capturing the meaning of words.
On the other hand, dense methods use more complex models, like neural networks, to create more compact and meaningful representations. These methods, such as REALM, DPR, and Sentence-Transformers, can understand the context and relationships between words better. However, they require more computational power and training time. Luckily, there are many pre-trained models available now, so you don't always have to train them from scratch. For a task like summarization, context has high importance and hence dense methods would produce significantly better embeddings for RAG. With numerous excellent models available, choosing the right embedding model for your RAG application can be challenging.
A helpful starting point is the MTEB Leaderboard on Hugging Face [https://huggingface.co/spaces/mteb/leaderboard], which offers a current list of proprietary and open-source text embedding models. This leaderboard provides insights into each model's performance on various embedding tasks such as retrieval and summarization. However, be aware that these results are self-reported and may have been benchmarked on different datasets. Additionally, some models might include the MTEB datasets in their training, so it's advisable to evaluate the model's performance on your specific dataset before making a final decision.
Retrieval
In the retrieval phase, the retriever searches through the vast knowledge base in the database to identify relevant information. The goal is to extract contextually relevant information that can enrich the generated content.The retrieval component aims to extract relevant information from a vast array of external knowledge sources. When the user enters a query or a prompt, it is this system (Retriever) that is responsible for accurately fetching the correct snippet of information that is used in responding to the user query. It involves two main phases, indexing and searching.
- Indexing organizes documents to facilitate efficient retrieval, using either inverted indexes for sparse retrieval or dense vector encoding for dense retrieval [24,25,26].
- The searching utilizes these indexes to fetch relevant documents on the user’s query, often incorporating the optional rerankers [26,27,28] to refine the ranking of the retrieved documents.
- According to LangChain’s 2023 State of AI survey, amongst the 6 most used retrieval searching strategies were Self Query, Contextual Compression, Multi-query and time weighted.

Source : LangChain State of AI 2023
- Similarity Search: Calculates distance between input and document embeddings for retrieval.
- Maximum Marginal Relevance (MMR): Reduces redundancy in retrieval, considering new information given previous results.
- Multi-query Retrieval: Uses language model to generate diverse queries for user input, retrieving relevant documents from each query and combining them for comprehensive results.
- Contextual Compression: Squeezes long documents to retain only important parts matching the search.
- Multi Vector Retrieval: Stores multiple vectors in a document for more efficient retrieval, matching with different types of information.
- Parent Document Retrieval: Stores small document chunks for better embeddings, retrieving larger documents using parent IDs during search.
- Self Query: System can ask itself questions, converting them into structured queries for more efficient and accurate searches.
- Time-weighted Retrieval: Supplements semantic similarity search with time delay, giving more weight to fresher or more used documents.
- Ensemble Techniques: Uses multiple retrieval methods in conjunction for improved results, with implementation depending on use cases.
The most optimal method to use will be task, data and domain dependent.
Generation
The generation component utilizes the retrieved content to formulate coherent and contextually relevant responses with the prompting and inferencing phases. The input for language models is formulated through prompting, integrating the query from the retrieval phase. Methods like Chain of Thought (CoT) [29] or Rephrase and Respond (RaR) [30] guide better generation results. In the inferencing step, Large Language Models (LLMs) interpret the prompted input to generate accurate and in-depth responses that align with the query’s intent and integrate the extracted information [31].
Advancements in NLP have led to substantial improvements in the quality and effectiveness of text summarization systems, paving the way for more accurate and contextually relevant summaries. While abstractive summarization techniques continue to evolve, driven by sophisticated models and techniques, RAG further enhances summarization by incorporating external, up-to-date information. By fusing the precision of retrieval and the creativity of generation, we unlock a new paradigm in summarization. As this model navigates context with precision, crafts summaries with creative finesse, and proves its mettle across diverse datasets, it heralds a future where summarization is not merely a task but an art form — a nuanced and intelligent expression of content understanding in the digital age.
References
- Yen-Chun Chen and Mohit Bansal. Fast abstractive summarization with reinforce-selected sentence rewriting. arXiv preprint arXiv:1805.11080, 2018.
- Ani Nenkova, Lucy Vanderwende, and Kathleen McKeown. A compositional context sensitive multidocument summarizer: Exploring the factors that influence summarization. In Proceedings of the 29th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, pp. 573–580, 2006.
- Ani Nenkova, Kathleen McKeown, et al. Automatic summarization. Foundations and Trends in Information Retrieval, 5(2–3):103–233, 2011.
- Josef Steinberger, Massimo Poesio, Mijail A Kabadjov, and Karel Ježek. Two uses of anaphora resolution in summarization. Information Processing & Management, 43(6):1663–1680, 2007.
- Yang Liu and Mirella Lapata. Text summarization with pretrained encoders. arXiv preprint arXiv:1908.08345, 2019.
- Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461,2019.
- Jingqing Zhang, Yao Zhao, Mohammad Saleh, and Peter Liu. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In International Conference on Machine Learning, pp. 11328–11339. PMLR, 2020a.
- Yixin Liu, Pengfei Liu, Dragomir Radev, and Graham Neubig. BRIO: Bringing order to abstractive summarization. arXiv preprint arXiv:2203.16804, 2022b.
- Tianyi Zhang, Faisal Ladhak, Esin Durmus, Percy Liang, Kathleen McKeown, and Tatsunori B Hashimoto. Benchmarking large language models for news summarization. Transactions of the Association for Computational Linguistics, 12:39–57, 2024.
- Liyan Tang, Zhaoyi Sun, Betina Idnay, Jordan G Nestor, Ali Soroush, Pierre A Elias, Ziyang Xu, Ying Ding, Greg Durrett, Justin F Rousseau, et al. Evaluating large language models on medical evidence summarization. NPJ Digital Medicine, 6(1):158, 2023.
- Dave Van Veen, Cara Van Uden, Louis Blankemeier, Jean-Benoit Delbrouck, Asad Aali, Christian Bluethgen, Anuj Pareek, Malgorzata Polacin, Eduardo Pontes Reis, Anna Seehofnerova, et al. Clinical text summarization: Adapting large language models can outperform human experts. Research Square, 2023.
- *Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., Wang, H., Chen, Q., Peng, W., Feng, X.,Qin, B., Liu, T.: A survey on hallucination in large language models: Principles, taxonomy,challenges, and open questions (Nov 2023). https://doi.org/10.48550/ARXIV.2311.05232*
- Zhang, Y., Khalifa, M., Logeswaran, L., Lee, M., Lee, H., Wang, L.: Merging Generated and Retrieved Knowledge for Open-Domain QA. In: Bouamor, H., Pino, J., Bali, K.(eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural LanguageProcessing. pp. 4710–4728. Association for Computational Linguistics, Singapore (Dec 2023). https://doi.org/10.18653/v1/2023.emnlp-main.286, https://aclanthology.org/2023.emnlp-main.286
- Yao, J.Y., Ning, K.P., Liu, Z.H., Ning, M.N., Yuan, L.: Llm lies: Hallucinations are not bugs,but features as adversarial examples. arXiv preprint arXiv:2310.01469 (2023)
- *https://arxiv.org/pdf/2310.20081v1*
- Jiuhai Chen, Lichang Chen, Chen Zhu, and Tianyi Zhou. 2023. How Many Demonstrations Do You Need for In-context Learning? arXiv:2303.08119 [cs.AI]
- Alireza Salemi, Sheshera Mysore, Michael Bendersky, and Hamed Zamani. 2023.LaMP: When Large Language Models Meet Personalization. arXiv preprint arXiv:2304.11406 (2023).
- Zheng Chen. 2023. PALR: Personalization Aware LLMs for Recommendation. arXiv preprint arXiv:2305.07622 (2023).
- Jinming Li, Wentao Zhang, Tian Wang, Guanglei Xiong, Alan Lu, and Gerard Medioni. 2023. GPT4Rec: A generative framework for personalized recommendation and user interests interpretation. arXiv preprint arXiv:2304.03879 (2023).
- Jiajing Xu, Andrew Zhai, and Charles Rosenberg. 2022. Rethinking personalized ranking at Pinterest: An end-to-end approach. In Proceedings of the 16th ACM Conference on Recommender Systems. 502–505.Shiran Dudy. 2022. Personalization and Relevance in NLG. In Companion Proceedings of the Web Conference 2022. 1178–1178.
- Lucie Flek. 2020. Returning the N to NLP: Towards contextually personalized classification models. In Proceedings of the 58th annual meeting of the association for computational linguistics. 7828–7838.
- Hongjin Qian, Xiaohe Li, Hanxun Zhong, Yu Guo, Yueyuan Ma, Yutao Zhu, Zhanliang Liu, Zhicheng Dou, and Ji-Rong Wen. 2021. Pchatbot: a large-scale dataset for personalized chatbot. In Proceedings of the 44th international ACM SIGIR conference on research and development in information retrieval. 2470–2477.
- Omid Rafieian and Hema Yoganarasimhan. 2022. AI and Personalization. Available at SSRN 4123356 (2022).
- *Blagojevic, V.: Enhancing RAG Pipelines in Haystack: Introducing DiversityRanker and LostInTheMiddleRanker (Aug 2023), https://towardsdatascience.com/enhancing-rag-pipelines-in-haystack-45f14e2bc9f5*
- Douze, M., Guzhva, A., Deng, C., Johnson, J., Szilvasy, G., Mazaré, P.E., Lomeli, M., Hosseini, L., Jégou, H.: The faiss library (2024)
- Khattab, O., Zaharia, M.: Colbert: Efficient and effective passage search via contextualized late interaction over bert (Apr 2020). https://doi.org/10.48550/ARXIV.2004. 12832
- Lyu, Y., Li, Z., Niu, S., Xiong, F., Tang, B., Wang, W., Wu, H., Liu, H., Xu, T., Chen, E., Luo, Y., Cheng, P., Deng, H., Wang, Z., Lu, Z.: Crud-rag: A comprehensive chinese benchmark for retrieval-augmented generation of large language models (Jan 2024).
https://doi
- . org/10.48550/ARXIV.2401.17043
- *Tang, Y., Yang, Y.: Multihop-rag: Benchmarking retrieval-augmented generation for multihop queries (Jan 2024). https://doi.org/10.48550/ARXIV.2401.15391*
- Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models (Jan 2022). https://doi.org/10.48550/ARXIV.2201.11903
- Deng, Y., Zhang, W., Chen, Z., Gu, Q.: Rephrase and respond: Let large language models ask better questions for themselves (Nov 2023). https://doi.org/10.48550/ARXIV.2311.04205
- Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis,M., Yih, W.t., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Tech. rep. (Apr 2021), http://arxiv.org/abs/ 2005.11401, arXiv:2005.11401 [cs] type: article
- https://arxiv.org/html/2211.00635v3#:~:text=The most common practice to,tasks via in-context learning.
.webp)



